
TABLE OF CONTENT
Data integration is a crucial process in organizations as it involves consolidating data from various sources to create a comprehensive, precise, and current dataset for applications such as business intelligence, data analysis, and other critical business operations. Data’s significance in shaping business decisions is widely acknowledged. This is where the Extract, Transform, Load (ETL) process plays a very important role in guaranteeing the accuracy, timeliness, and accessibility of the data. In this blog, we will discuss more about the ETL strategies for a smooth and effective data integration process.
What is ETL?
ETL stands for Extract, Transform, and Load. It is a process of extracting data from various sources, transforming the data to fit a specific format or structure, and loading the data into a target database or data warehouse. ETL process enables businesses to integrate data from multiple sources, which can help identify patterns, trends, and relationships.
During the early 1970s, as databases became increasingly popular, ETL emerged as a reliable method for integrating and loading data for analysis and computation and quickly became the preferred method for data processing in many data warehousing projects. Today, ETL is considered the cornerstone of data analytics and machine learning workflows. Using predefined business rules, ETL processes data, cleans it, and organizes it to meet specific business intelligence needs, from simple monthly reporting to more advanced analytics that can enhance back-end processes and user experiences.
How does it work?
The ETL process begins with data extraction, which involves identifying and retrieving data from various sources such as databases, cloud-based services, and flat files. The extracted data is then transformed using data mapping, filtering, aggregation, and other techniques to fit the target schema. Finally, the transformed data is loaded into a target database or warehouse.
Extraction:
In the ETL architecture, the first step involves extracting data from the source system into the staging area. The staging area is a buffer between the source system and the data warehouse database. Any transformations, if required, are performed in the staging area to prevent performance degradation of the source system. Moreover, copying corrupted data directly from the source into the data warehouse can make rollback a challenging task. The staging area allows validation of the extracted data before it is moved into the data warehouse.
Data warehousing involves integrating data from multiple systems with different DBMS, hardware, operating systems, and communication protocols. These systems can include legacy applications, customized applications, point-of-contact devices like ATMs, call switches, text files, spreadsheets, ERPs, and data from vendors or partners, among others. Therefore, a logical data map is necessary before data is extracted and physically loaded. This data map describes the relationship between sources and target data.
There are three methods of data extraction
- Complete Extraction – All data is extracted every time, which can be time-consuming and put a load on the source system.
- Partial Extraction without Update Notification – Only new data since the last extraction is extracted. However, the existing data is not captured, leading to incomplete data warehouse data.
- Partial Extraction with Update Notification – Only new data since the last extraction is extracted, and any updates to existing data are captured, ensuring complete data in the data warehouse.
Regardless of the method used, the extraction process should not affect the performance and response time of the source systems, as they are live production databases. Any slowdown or locking of these systems could significantly impact the company’s bottom line.
Transformation:
The second step of the ETL process is transformation, where the raw data extracted from the source server is cleansed, mapped, and transformed into a usable form for generating insightful BI reports.
Direct move or pass-through data does not require any transformation.
In this step, customized operations can be performed on data, such as the respective columns or calculating a sum of sales revenue.
Data integration issues can arise due to different spellings of the same name, multiple ways to denote company names, other naming conventions, multiple account numbers for the same customer, blank files, invalid products, etc.
Validation checks are performed during this stage, including filtering, using rules and lookup tables, character set conversion, unit conversions, data flow validation, cleaning, splitting, and merging columns, transposing rows and columns, using lookups to connect data, and applying complex data validation.
Loading
The third step of the ETL process is loading data into the target data warehouse database, which should be optimized for performance as it involves enormous volumes of data. Recovery mechanisms should be in place in case of load failure to avoid data integrity loss. There are three types of loading: initial, incremental, and full refresh. Load verification includes ensuring critical field data is not missing or null, testing modeling views, checking combined values and calculated measures, and verifying BI reports. Monitoring, resuming, and canceling loads is the responsibility of the Data Warehouse admins.
ETL Vs. ELT
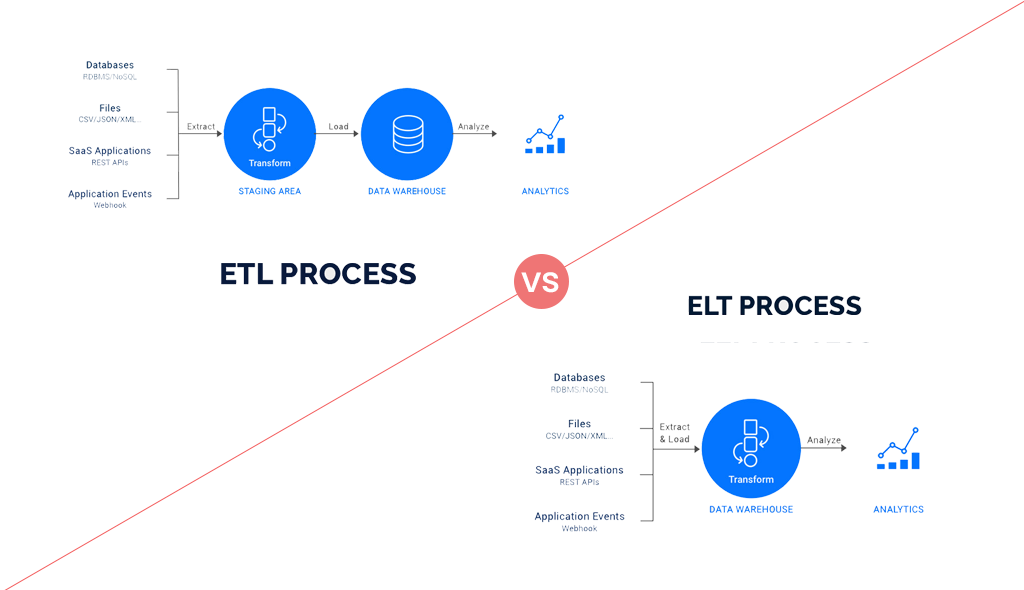
ETL and ELT (Extract, Load, Transform) are data integration processes. The main difference between the two is the order of the transformation process. In ETL, data is transformed before being loaded into a target database, while in ELT, data is loaded into the target database before being converted. ELT is preferred in cases where the target database has a high processing capacity, while ETL is preferred in cases where data transformation is complex and resource-intensive.
ELT & Other data integration methods
Besides ETL and ELT, there are other data integration methods, such as data replication, change data capture, and data virtualization. Data replication involves copying data from one database to another. Change data capture (CDC) captures changes made to source data and applies them to the target database. Data virtualization creates a virtual layer between the data sources and the target database, enabling real-time access to data without physical integration.
The benefits and challenges of ETL
ETL offers several benefits, including:
- Improved data quality: ETL ensures the data is accurate, consistent, and up-to-date.
- Faster access to data: ETL enables businesses to access data from multiple sources in a structured format, which can help speed up decision-making.
- Scalability: ETL is scalable and can handle large volumes of data.
- Cost-effective: ETL reduces the need for manual data integration, which can save time and reduce costs.
However, ETL also poses some challenges, such as:
- Complexity: ETL requires technical expertise to design and implement.
- Time-consuming: ETL can be time-consuming, especially when dealing with large volumes of data.
- Maintenance: ETL requires regular maintenance to maintain its functioning correctly.
ETL Solutions
There are several ETL solutions available in the market that can help streamline the data integration process. Some popular ETL tools include Talend, Microsoft SQL Server Integration Services (SSIS), Informatica PowerCenter, and Oracle Data Integrator (ODI). These solutions offer a range of features, such as data mapping, data transformation, and data quality checks.
ETL Best practices
To ensure a smooth and effective ETL process, it is essential to follow best practices such as:
- Define precise requirements: Clearly define the needs of the ETL process, including the source and target systems, data mapping, and data transformation.
- Test thoroughly: Test the ETL process to identify and address any issues before deployment.
- Automate where possible: Automate repetitive tasks to reduce the risk of errors and save time.
- Document the process: Document the ETL process to ensure that it can be replicated or updated if necessary.
ETL Next Generations
ETL is evolving rapidly, and several emerging trends in ETL are shaping the future of data integration. Some of the key trends include:
- Cloud-based ETL solutions that offer greater scalability and flexibility
- The use of artificial intelligence (AI) and machine learning (ML) to automate and optimize the ETL pro- The adoption of real-time ETL to enable faster data processing and analysis
- The integration of ETL with other data management technologies like data warehousing and data lakes
- Codeless ETL development: Next-generation ETL tools provide a graphical user interface (GUI) that allows developers to drag and drop pre-built data connectors, transformations, and other components to build ETL workflows without writing any code.
- Intelligent data mapping: These tools use AI and ML algorithms to automatically map data from different sources to the target data model, reducing the need for manual mapping.
- Real-time data integration: Next-generation ETL tools support real-time data integration, allowing businesses to access and analyze data in near-real-time.
- Data quality management: These tools provide advanced data profiling and cleansing capabilities, allowing businesses to ensure data accuracy and completeness.
- Cloud-based infrastructures: Next-generation ETL tools leverage cloud-based infrastructures to handle large volumes of data and provide more flexibility and scalability.
ETL Tools
As mentioned earlier, there are several ETL tools available in the market, and choosing the right tool can be a daunting task. Some factors to consider when selecting an ETL tool include:
-The tool’s ability to handle data volumes and complexity
– The level of automation and customization offered
– The tool’s scalability and performance
– The tool’s integration with other technologies like cloud platforms and databases
– The cost and licensing model of the tool
Conclusion
In conclusion, the ETL process is essential for businesses looking to integrate data from various sources into a central database or data warehouse. W2S Solutions offers expert Data Engineering Services, leveraging the latest tools and technologies, to ensure a seamless and effective data integration process. With our services, businesses can make informed decisions and gain a competitive edge in their industry.
To know more about the services and the technologies-related queries reach out to the case study undergone with our experts below here.
Frequently Asked Questions
To plan an ETL project, you should:
- Define the project scope and objectives
- Identify the data sources and target system(s)
- Define the data extraction, transformation, and loading requirements
- Develop a project plan and timeline
- Identify the resources needed, including personnel and technology
- Develop a testing plan and quality assurance procedures
Get inspired!
Subscribe to our newsletter and get updates on how to navigate through disruption and make digital work for your business!








